
1 – Formas de analizar en Screaming Frog
Screaming Frog permite diferentes maneras de abordar un análisis SEO, en función del objetivo que tengamos. Por un lado, podemos hacer un rastreo “en bruto”, sin aplicar filtros ni configuraciones previas, lo que nos da una visión completa de la web tal como es. Pero también podemos configurar previamente el rastreo para centrarnos en aspectos concretos, como seguir enlaces nofollow, analizar sólo ciertas secciones del sitio o respetar el robots.txt. Esta personalización es clave para adaptar el análisis a cada necesidad específica.
2 – El Sitemap en Screaming Frog
Screaming Frog puede usar el sitemap XML como base para el rastreo. Esto es muy útil para comprobar qué URLs están indexadas y cómo están configuradas, comparándolas con lo que realmente está enlazado internamente.

Para ello, basta con ir a:
Configuración -> Spider -> Rastreo -> Rastrear sitemaps XML enlazados
Desde ahí, tenemos dos opciones:
-
Dejar que Screaming Frog detecte el sitemap automáticamente desde el
robots.txt. -
O introducir manualmente la URL del sitemap.
Además, si queremos auditar exclusivamente las URLs del sitemap, podemos usar el modo Lista. Simplemente descargamos el sitemap, lo cargamos en SF, y obtenemos toda la información sobre esas URLs en concreto.
3 – Configuraciones Típicas antes de Analizar
Antes de empezar un rastreo serio, conviene revisar algunas configuraciones clave:
-
Seguir enlaces nofollow internos: en ocasiones, es útil activar esta opción para tener una imagen completa del enlazado.
-
Incluir los sitemaps en el rastreo.
-
Si el sitio utiliza un CDN, conviene indicar la IP o hostname correspondiente.
-
Excluir parámetros en la URL que no aportan contenido relevante, especialmente si hay muchos. Esto se hace desde:
Configuración -> Reescritura de URL -> Eliminar Todos
-
Velocidad de rastreo: importante ajustar este valor para no sobrecargar el servidor. Un rastreo demasiado rápido puede provocar bloqueos o errores.
-
Elegir un User-Agent adecuado: si detectamos bloqueos, podemos cambiar el agente a uno más “amigable”, como Googlebot.
4 – Robots.txt en Screaming Frog
Screaming Frog permite gestionar cómo trata el archivo robots.txt:
Configuración -> Robots.txt
Ahí podemos decidir si queremos:
-
Respetar las reglas del archivo.
-
Ignorarlas completamente.
Esto afectará directamente a qué URLs se rastrean. Las bloqueadas aparecerán en el panel lateral como tales. Si se mezclan URLs externas, podemos usar filtros por dominio para centrarnos sólo en las nuestras. Este paso es muy útil para detectar si hay URLs importantes (como fichas de producto o categorías) bloqueadas por error.
5 – Probador de Robots.txt
Dentro del propio panel de configuración de robots, Screaming Frog incluye un probador de reglas.
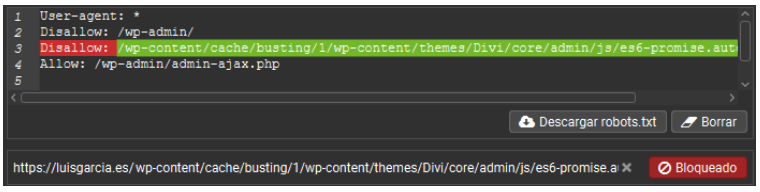
Funciona de forma similar al tester de robots de Google y nos permite simular el comportamiento del crawler sobre una URL concreta. Es perfecto para validar si el robots.txt está bloqueando contenidos sin que lo sepamos.
6 – Datos Estructurados
Screaming Frog puede detectar y extraer datos estructurados como Schema.org o JSON-LD, siempre que activemos esta opción en:
Configuración -> Extracción -> Datos Estructurados
Una vez habilitado, los resultados se mostrarán en el panel inferior y podremos revisar si están bien implementados o si hay errores.
7 – Análisis del Anchoring Interno
El análisis de los textos ancla (anchor text) permite ver cómo se está distribuyendo el enlazado interno. Podemos exportarlos desde:
Exportación en Bloque -> Enlaces -> Todos los textos ancla
Esto es clave para comprobar si estamos usando una buena variedad de anclas o si estamos sobreoptimizando.
8 – Posición de los Enlaces Internos
Además del texto, Screaming Frog nos permite ver dónde están ubicados los enlaces. Esto es relevante porque no es lo mismo un enlace en el menú que uno en el contenido principal.

Para configurarlo:
Configuración -> Personalizada -> Posición de los Enlaces
Ahí introducimos las clases o IDs HTML que queremos identificar. Luego, al seleccionar una URL en el panel, en la pestaña Enlaces Internos, podemos ver la columna “Posición del Enlace” con esta información.
10 – Xpath
Screaming Frog permite usar expresiones XPath para extraer información concreta de la web de forma automatizada. XPath es un lenguaje que sirve para navegar estructuras XML y HTML, ideal para localizar elementos específicos dentro del código.
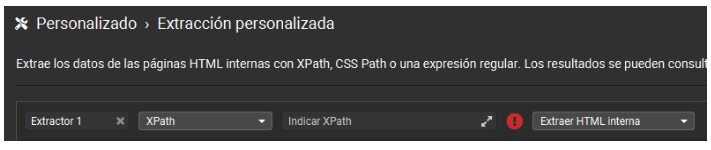
Por ejemplo, si queremos extraer precios, descripciones o títulos personalizados, configuramos la extracción en:
Configuración -> Extracción personalizada -> XPath
Es fundamental saber con precisión qué parte del HTML queremos analizar. Para ello, conviene inspeccionar el código de la página primero.
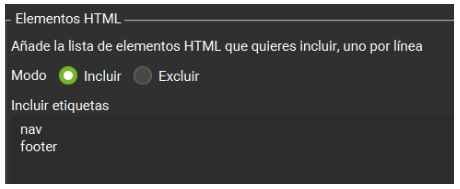
11 – Contenido Duplicado
Para detectar contenido duplicado, Screaming Frog compara la similitud entre páginas usando un porcentaje que podemos definir. Normalmente, se considera “semiduplicado” a partir del 20% de coincidencia.
Pero hay un paso importante: indicar qué parte del contenido debe analizarse, excluyendo elementos repetitivos como el header, footer o sidebar. Esto se configura en:
Configuración -> Contenido -> Área de Contenido
Ahí podemos incluir o excluir por etiquetas, clases o ID. De esta forma nos centramos sólo en el contenido relevante.
12 – Redirecciones Internas
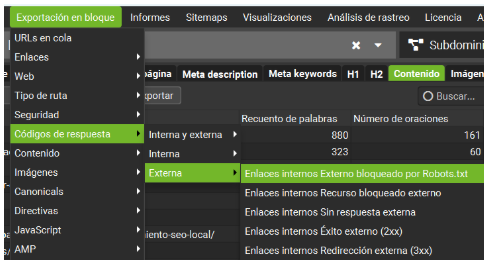
Podemos exportar un listado de todas las redirecciones internas para detectar posibles errores. Esto es muy útil para:
-
Corregir enlaces que apuntan a URLs con código 301 (innecesarios si podemos enlazar directamente a la versión final).
-
Localizar enlaces a páginas 404, que generan errores y afectan al SEO.
Para ello, usamos la exportación en bloque en el informe de redirecciones.
13 – Enlazado Interno
El enlazado interno es uno de los pilares del SEO técnico. Con Screaming Frog podemos:
-
Ver cuántos enlaces recibe cada URL.
-
Identificar páginas huérfanas o poco enlazadas.
-
Analizar la distribución del link juice.
Esto se hace desde el panel principal, en la pestaña “Internos”, o a través de exportaciones.
14 – Almacenamiento en Base de Datos
Por defecto, Screaming Frog almacena los rastreos en memoria, lo que puede limitar el análisis si el sitio es muy grande. Una alternativa es activar el almacenamiento en Base de Datos:
Archivo -> Configuración del Almacenamiento -> Base de Datos
Esto nos permite guardar crawls completos y compararlos posteriormente. Muy útil para auditorías recurrentes o comparaciones tras una migración.
15 – Detectar Páginas Huérfanas
Una página huérfana es aquella que no recibe ningún enlace interno, pero puede estar indexada o recibir tráfico.
Para detectarlas:
-
Cargamos manualmente los sitemaps.
-
Conectamos las APIs de Google Analytics y Search Console.
-
Activamos la opción:
Configuración -> API de GA/GSC -> Rastrear nuevas URL descubiertas
Después del rastreo, vamos a:
Informes -> URL’s Huérfanas
Ahí veremos qué páginas reciben tráfico pero no están enlazadas internamente.
16 – Rastrear Sitios Grandes

Cuando analizamos webs con miles o millones de URLs, conviene:
-
Usar el modo de almacenamiento en base de datos.
-
Limitar la profundidad del rastreo.
-
Ajustar la velocidad de escaneo.
-
Usar filtros por carpetas o URL.
Esto mejora el rendimiento y evita que Screaming Frog colapse o que el servidor del sitio se sature.
17 – Rastrear Sitios con JavaScript
Muchas webs modernas cargan contenido dinámico con JS. Para detectar si una web usa JavaScript:
-
Usamos la extensión Web Developer y desactivamos el JS.
-
Si al recargar la web no se ve nada, significa que depende de JS.
Para rastrear ese contenido, activamos:
Configuración -> Renderizado -> JavaScript
Y podremos ver qué contenido ha sido renderizado correctamente en la pestaña Rendered Page.
18 – Migraciones con Screaming Frog
Caso 1: Comprobar redirecciones
-
Activamos Always Follow Redirects.
-
Subimos las URLs antiguas en modo lista.
-
Vamos a Informes -> Redirecciones -> Todas las redirecciones.
Así vemos si:
-
Las redirecciones llevan a páginas correctas.
-
Se están generando bucles o cadenas de redirección.
Caso 2: Comparación avanzada de rastreos
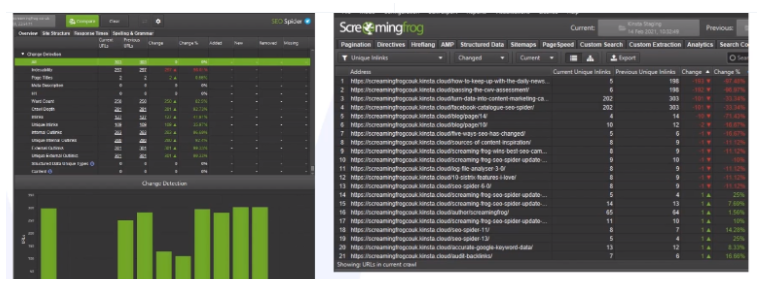
-
Rastrear el sitio en el entorno previo a la migración.
-
Rastrear la versión en producción.
-
Seleccionar el modo Compare, siempre que el almacenamiento esté en Base de Datos.
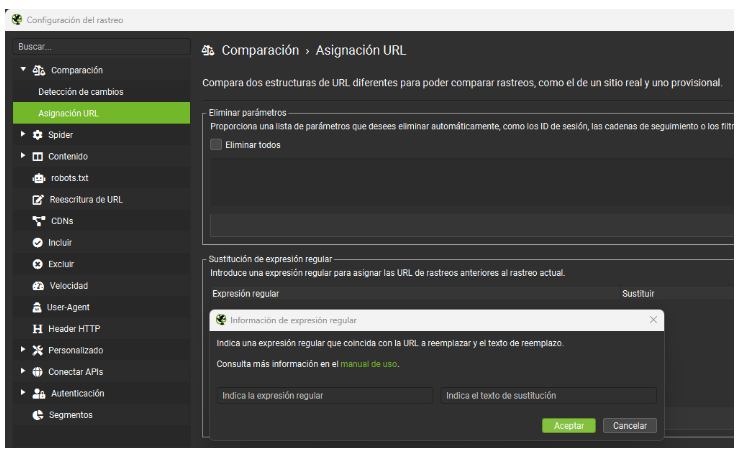
Si los dominios son distintos (por ejemplo, un entorno staging), podemos usar:
Configuración de Comparación -> Sustitución por Expresión Regular
Esto permite igualar URLs distintas y comparar correctamente los dos entornos.
19 – Incluir y Excluir Carpetas en Rastreo
Podemos limitar el rastreo a ciertas secciones de la web desde:
Configuración -> Incluir / Excluir
Esto es útil cuando solo queremos analizar un subdirectorio (como /blog o /productos), o si queremos evitar zonas como /admin o /privado.

20 – Parámetros en URLs
Los parámetros pueden distorsionar el rastreo si no se controlan. En Screaming Frog podemos:
-
Omitir todos los parámetros.
-
O excluirlos individualmente desde:
Configuración -> Reescritura de URL
Además, podemos limitar el número de cadenas de consulta desde:
Configuración de Rastreo -> Límites -> Número de parámetros

Diferencia entre:
-
Parámetros activos: modifican el contenido.
-
Parámetros pasivos: como los UTM, que no lo modifican.
21 – Tiempo de Respuesta y WPO
Para medir el rendimiento de carga de la web, tenemos dos opciones:
-
Ver el tiempo de respuesta en un rastreo normal.
-
Conectar la API de PageSpeed Insights y seleccionar las métricas que nos interesan.
Los resultados se muestran en el panel habitual y permiten detectar páginas lentas.
22 – Niveles de Profundidad
Screaming Frog muestra automáticamente el nivel de profundidad (número de clics desde la home) en la columna “Depth” dentro de la pestaña Internos.
Se recomienda que el contenido importante esté a menos de 3 clics de la página principal.
23 – SEO Internacional
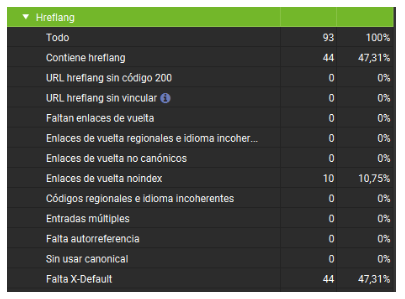
Para analizar la etiqueta hreflang, debemos habilitar esta función:
Configuración -> Spider -> SEO Internacional
Una vez activado, veremos la información en el panel lateral. Esto nos permite detectar errores en la implementación del SEO multidioma.
24 – Rastrear Sitios con Login
Algunas webs muestran contenido diferente a los usuarios registrados. Para rastrearlo:
Configuración -> Autenticación -> Basada en Formularios
Introducimos la URL del login, accedemos con nuestras credenciales, y a partir de ahí Screaming Frog rastreará como si estuviéramos logueados.
25 – Paginaciones
Para rastrear correctamente la relación entre páginas paginadas:
Configuración -> Paginación rel=»next/prev» -> Habilitar
Esto nos permite auditar el marcado correcto de la paginación y detectar errores en el enlazado entre páginas.
26 – Enlaces a Recursos Inseguros
Después del rastreo, podemos comprobar si alguna URL está cargando contenido desde fuentes no seguras (HTTP):
Ir a la pestaña Seguridad
Seleccionar el filtro URL HTTP
Ahí veremos todos los recursos inseguros, que pueden generar advertencias en navegadores o afectar al SEO.



